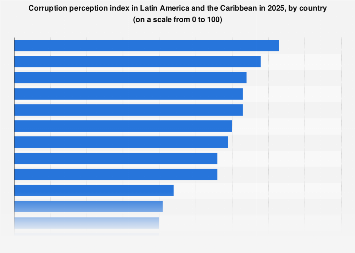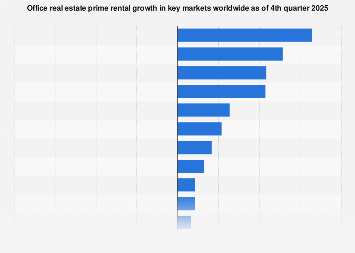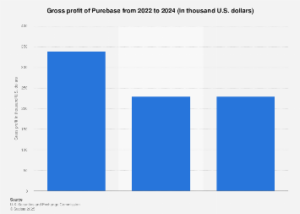

The burgeoning field of artificial intelligence, particularly the rapid advancements in large language models (LLMs), compels a deeper examination of the fundamental principles governing both machine and human cognition. Professor Tom Griffiths, a distinguished researcher in artificial intelligence and cognitive science at Princeton University, posits that centuries of mathematical inquiry into the workings of the mind provide the essential frameworks for understanding contemporary AI. His work, notably highlighted in his book The Laws of Thought, traces the intellectual lineage of three core approaches – rules and symbols, neural networks, and probability theory – demonstrating their individual strengths, historical evolution, and crucial interconnectedness in shaping modern intelligent systems.
Historically, the quest to formalize thought began with the "rules and symbols" paradigm. This approach, rooted in the mathematical logic pioneered by figures like George Boole in the 19th century, sought to describe mental processes through explicit, verifiable rules and symbolic representations. Boole’s "laws of thought" laid the groundwork for mathematical logic, which subsequently became the bedrock of computer science through the contributions of Alan Turing and John von Neumann. Early artificial intelligence, particularly in the mid-20th century, heavily leaned on this framework, developing expert systems and symbolic AI that excelled in deductive reasoning, problem-solving, and structured tasks. Cognitive scientists, in their nascent efforts to rigorously study the unseen mechanisms of the mind, found these logical principles invaluable for formulating precise hypotheses about how humans might process information, including the structural aspects of language as articulated by Noam Chomsky. While effective for tasks with clear, well-defined parameters, this paradigm eventually encountered significant limitations, notably its struggles with learning from data and its inability to elegantly capture the "fuzzy boundaries" and nuances inherent in real-world concepts and human language. For instance, classifying an "olive" as a "fruit" often elicits human uncertainty that rigid symbolic logic struggles to represent, showcasing a critical gap in its explanatory power for organic cognition.
A significant pivot occurred with the advent of "neural networks," a paradigm that emerged from attempts to model the brain’s biological structure. By the mid-20th century, and gaining substantial traction from the 1980s onwards, researchers began exploring continuous representations of concepts, where entities are points in abstract spaces defined by their features. This shift necessitated a different mathematical language, one capable of describing continuous functions and relationships. Artificial neural networks, inspired by biological neurons, offered a powerful mechanism for learning these complex, non-linear relationships directly from vast datasets. They proved adept at solving the learning problem that had stymied symbolic AI, demonstrating remarkable capabilities in pattern recognition, classification, and generalization from examples. This framework underpins the current explosion in deep learning, enabling breakthroughs in image recognition, speech processing, and ultimately, the sophisticated language understanding capabilities seen in today’s generative AI models. The market impact of this approach is staggering, with global AI spending projected to exceed $500 billion by 2027, largely driven by advancements in deep learning applications. While powerful, early neural networks often operated as "black boxes," making their internal decision-making processes opaque and raising questions about interpretability and robust generalization.
The third critical framework, "probability and statistics," offers a lens for understanding inductive inference and managing uncertainty. Statistics, as the science of drawing conclusions from data, and probability theory, as the tool for quantifying uncertainty, provide a robust mathematical basis for how intelligent systems can make informed guesses when complete information is unavailable. This framework is crucial for comprehending why neural networks achieve their impressive learning capabilities. In the context of large language models, for example, their primary training objective is often to predict the next token (word or sub-word unit) in a sequence based on prior context, which is inherently a probabilistic task. This Bayesian approach allows LLMs to model the likelihood of various linguistic constructs, enabling them to generate coherent and contextually relevant text. Moreover, probabilistic reasoning is increasingly vital for enhancing the reliability and trustworthiness of AI systems, particularly in high-stakes applications where understanding confidence levels and potential biases is paramount. Its integration helps explain phenomena like concept learning from limited data, a common human cognitive ability that current AI systems often struggle to replicate without massive datasets.
Rather than being competing philosophies, Griffiths emphasizes that these three mathematical frameworks are complementary, offering different levels of analysis for understanding intelligence. Drawing on the work of theoretical neuroscientist David Marr, he outlines three explanatory levels: the computational level (what problem is being solved and what is the optimal solution?), the algorithmic level (what processes are used to solve it?), and the implementation level (how are these processes physically realized?). In this hierarchy, logic and probability theory primarily operate at the abstract computational level, describing how an ideal agent should solve problems—whether deductive (given all information) or inductive (inferring from incomplete information). Neural networks, conversely, provide the mechanisms for the algorithmic and implementation levels, offering concrete strategies for approximating solutions to these abstract mathematical problems within a physical or computational system. This integrated perspective is driving the emergence of "neuro-symbolic AI," a hybrid approach that seeks to combine the strengths of both symbolic reasoning and neural network learning to build more robust and interpretable intelligent systems.
Language serves as a compelling case study for the interplay of these three paradigms. Chomsky’s foundational work in linguistics highlighted the rule-bound, symbolic structure of grammar, describing how sentences are constructed from nouns, verbs, and specific syntactic rules. However, this framework struggled to explain language acquisition—how human children learn complex grammatical structures without explicit instruction. Neural networks provided a breakthrough, demonstrating that systems could learn grammatical rules implicitly from data, often without explicitly representing concepts like "noun" or "verb." This shift enabled a data-driven approach to natural language processing that revolutionized the field. Probability theory further enriches this understanding by explaining the inductive aspects of language, such as how humans infer meaning from ambiguous utterances or predict upcoming words in a conversation. Modern large language models perfectly illustrate this synergy: they are trained on vast corpora of multi-modal data, including natural language (English, French, Mandarin, etc.) and programming code (which provides a rich symbolic structure), using massive artificial neural networks, and their training objective is fundamentally probabilistic—predicting the next token. This multi-faceted approach allows LLMs to manifest remarkable linguistic capabilities, with significant global economic implications for communication, content creation, and information retrieval.
Despite their rapid progress, current AI systems exhibit fundamental differences from human intelligence, largely due to divergent operational constraints. Human intelligence evolved under strict limitations: finite lifespans (limiting data exposure), constrained neural tissue (limiting computational resources), and low-bandwidth communication (inefficient information transfer). Conversely, AI systems face fewer such constraints: access to exponentially larger datasets, scalable computational power (though energy-intensive), and high-bandwidth information transfer (e.g., sharing model weights). This divergence leads to different strengths. While AI can process immense data to recognize complex patterns, it often struggles with "one-shot" learning or systematic generalization beyond its training distribution, a forte of human cognition. For instance, humans can learn a new word from a single exposure or intuitively grasp complex mathematical principles without millions of examples, a challenge for LLMs in handling truly novel, long-form numerical operations.
This is where human "inductive bias" and "metacognition" become critical differentiators. Inductive bias refers to the inherent assumptions a learner brings to a problem, guiding them to prefer certain explanations over others when faced with limited data. Humans possess systematic inductive biases that enable efficient learning and robust generalization from sparse information. Metacognition, on the other hand, involves thinking about one’s own thinking – the ability to monitor, regulate, and assess cognitive processes. This includes strategic problem-solving, identifying appropriate tools for a task, and evaluating the reliability of information. In an AI-augmented world, metacognitive labor – management, curation, judgment, and the strategic deployment of AI tools – will become increasingly valuable. As AI systems take over more cognitive tasks, humans will focus on defining problems, setting objectives, interpreting results, and providing the crucial "common sense" and ethical oversight that AI currently lacks.
The implications for the future of work and human-AI collaboration are profound. Rather than viewing AI as a replacement for human intelligence, a more productive perspective emphasizes complementarity. AI systems, shaped by different constraints and optimized for specific tasks, will excel in areas requiring massive data processing, rapid computation, and precise pattern recognition. Humans, with their unique capacities for metacognition, small-data generalization, nuanced judgment, and creative problem definition, will provide the strategic direction and ethical framework. This necessitates developing more intuitive interfaces and potentially even new "languages" for human-AI interaction, enabling more efficient communication of complex concepts and intentions. Ultimately, understanding the mathematical foundations of both human and artificial intelligence allows for a more realistic assessment of AI’s capabilities and limitations, fostering a future where intelligent machines serve as powerful tools, augmenting human potential rather than merely mimicking or superseding it. This nuanced perspective encourages the strategic development of AI systems that are reliable, align with human values, and work harmoniously alongside human intellect to address global challenges.